音声学習・再現のGPT-SoVITS トレーニング・推論編

わずか5秒の音声データがあれば、声を再現でき、なおかつ多言語にも変換可能なTTS、GPT-SoVITSを試しながら、その設定方法などをまとめていきたいと思います。今回はトレーニング・推論編。
インストール編は「音声学習・再現のGPT-SoVITS インストール編」をご覧ください。
GPT-SoVITSの特徴
ゼロショットでTTS
5秒のボイスサンプルがあれば音声変換可能
ファーショットTTS
1分のトレーニングデータでモデルをファインチューニングし、声の類似性をさらい向上
クロスリンガル
トレーニングセットとは異なる言語で推論し英語、日本語、中国語に変換
WebUI ツール
統合されたツールには、音声伴奏の分離、トレーニングセットの自動セグメンテーション、中国語 ASR、テキストラベリングが含まれ、初心者がトレーニングデータセットと GPT/SoVITS モデルを作成するのを支援。
起動
GPT-SoVITSフォルダ内のgo-webui.batをダブルクリックで起動します。その後「1-GPT-SoVITS-TTS」のタブを開き、さらに「1-C推論」タブを開き、下部の「TTS推理WebUIを開始しますか?」をチェックを入れます。しばらく待つと、ブラウザの別タブが開き以下のような画面が表示されれば推論の準備は完了です。
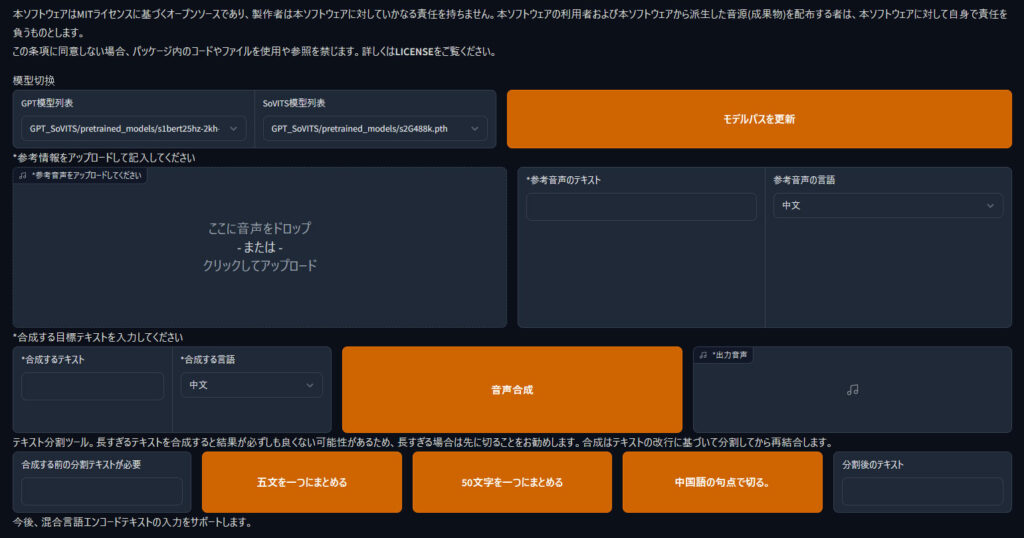
推論
参考音声をアップロード、音声のテキストを転記、合成するテキストを入力して音声合成を行えば音声が合成されます。
今回はサンプルを制作する上で、「つくよみちゃんコーパス│声優統計コーパス(JVSコーパス準拠)」というフリー素材キャラクター「つくよみちゃん」が無料公開している音声データを使用しています。を利用させていただきました。
推論結果は?
わずか8秒の音声から生成されたとは思えない、超高精度な再現となりました。これは様々なコンテンツに利用できそうです。
GPT-SoVITS
https://github.com/RVC-Boss/GPT-SoVITS










