音声学習・再現のGPT-SoVITS インストール編

わずか5秒の音声データがあれば、声を再現でき、なおかつ多言語にも変換可能なTTS、GPT-SoVITSを試しながらその設定方法などをまとめていきたいと思います。今回はインストール編として起動までの手順をまとめます。
GPT-SoVITSの特徴
ゼロショットでTTS
5秒のボイスサンプルがあれば音声変換可能
ファーショットTTS
1分のトレーニングデータでモデルをファインチューニングし、声の類似性をさらい向上
クロスリンガル
トレーニングセットとは異なる言語で推論し英語、日本語、中国語に変換
WebUI ツール
統合されたツールには、音声伴奏の分離、トレーニングセットの自動セグメンテーション、中国語 ASR、テキストラベリングが含まれ、初心者がトレーニングデータセットと GPT/SoVITS モデルを作成するのを支援。
インストール
windowsユーザー向けには7zで圧縮された統合版が用意されているのでそちらが便利です。zip をダウンロードして解凍し、go-webui.bat をダブルクリックするだけで GPT-SoVITS-WebUI が起動します。
ファイルは7zipで圧縮されているので、7-Zipファイルアーカイバなどを利用して展開しましょう。
詳細は公式のReadMeを参照。日本語のReadmeも用意されています。
https://github.com/RVC-Boss/GPT-SoVITS/blob/main/docs/ja/README.md
必要な環境
Python 3.9, PyTorch 2.0.1, CUDA 11
Python 3.10.13, PyTorch 2.1.2, CUDA 12.3
Python 3.9, PyTorch 2.3.0.dev20240122, macOS 14.3 (Apple Silicon, MPS)
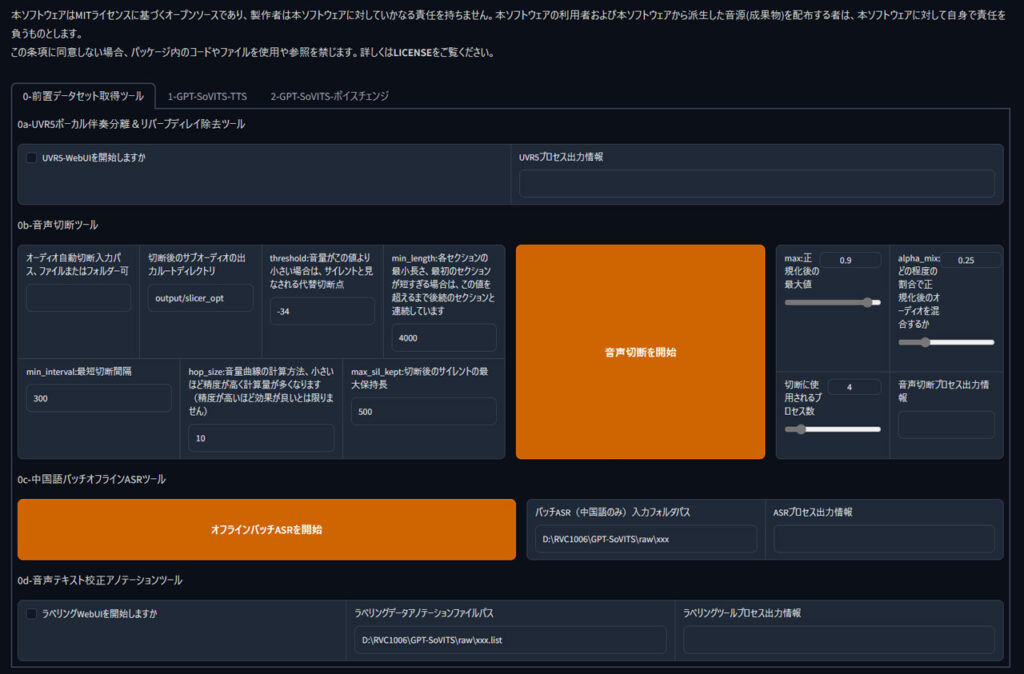
webUIの起動
ダウンロード・展開が完了したらフォルダ内のgo-webui.batをダブルクリックで起動します。ブラウザ上に下記のUIが表示されれれば起動は完了です。
GPT-SoVITS
https://github.com/RVC-Boss/GPT-SoVITS