ChatGPTプラグイン「SceneXplain」- 画像を解析して含まれる要素をテキスト化

ChatGPTプラグインを実際の生成例を交えながら紹介していきます。今回紹介するのはChatGPTプラグイン「SceneXplain」。
ChatGPTプラグイン「SceneXplain」について
「SceneXplain」は、指定した画像URLから、その画像がどんな画像なのか、画像内にどんな要素が含まれているのかをテキストで解析してくれるプラグインです。日本語で指示すれば、解析結果も日本語で返答してくれます。
ChatGPTのプラグインとは?
OpenAIが、ChatGPTを拡張するための機能として、「プラグイン(Plugins)」をリリース。
「プラグイン(Plugins)」は、ChatGPTを多機能にカスタマイズ、拡張するための機能です。現状は有料のChatGPT Plusユーザーに限定されています。
ChatGPTのプラグインについての利用法については、「プラグインを利用してChatGPTを拡張する<インストール〜実行まで>」の記事をご覧ください。
ChatGPTのプラグイン「SceneXplain」の使い方
Plugin storeのSearchから「SceneXplain」を検索、Installボタンを押してChatGPTにプラグインをインストールします。
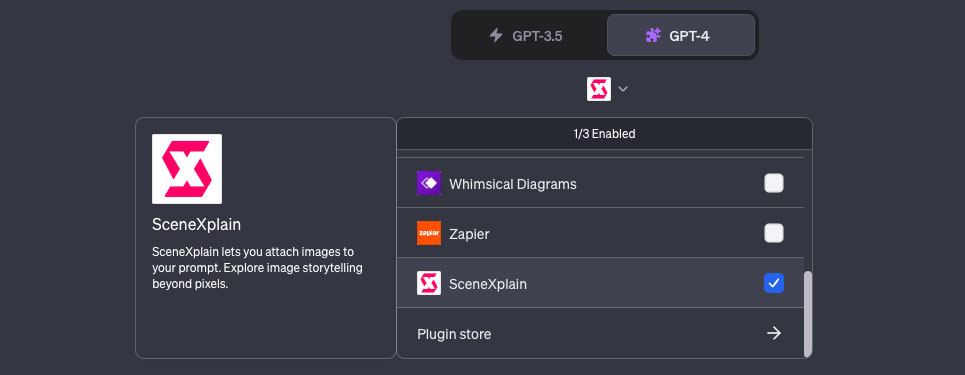
プラグインはGPT-4モデルでの利用となるので、GPT-4のタブからPluginsを選択、プルダウンメニューからプラグイン一覧から「SceneXplain」をチェックすれば準備は完了です。
「SceneXplain」プラグインの利用例
今回は以下のwikipediaでパブリックドメインで公開されている富士山の画像を指定して解析してもらいました。


富士山という固有名詞は現れませんし、オレンジも熟していないし、飛行機も飛んでいないませんが、他の事例だと固有名詞が出てくる事例もあったので、精度は読み込ませる画像に大きく依存しそうです。
「SceneXplain」プラグインの使い所
画像を解析し対象物をテキストで抽出してくれることで、単純にキャプションコピーの生成や、コピーライティングの補助としてのベースに利用できそうです。また、他にも画像生成AIで同じような画像を生成したい時のヒントにするなどの活用方法も考えられそうです。










