RVCを利用して学習した音声モデルの使い方を解説

「声の機械学習をRVCで実施する方法」という記事でRVCを使った音声学習についてお伝えしましたが、今回は生成した音声モデルを利用して学習された音声を使う方法を紹介します。
大きく分けて、既存の音声から音声モデルを使って推論する形と、リアルタイムにボイスチェンジャーを利用して音声変換する方法がありますが、今回はまず、既存の音声データを書き換える方法をご紹介します。
※RVC v2についての解説は「音声学習のRVCに、新たな学習モデルRVC v2が追加」をご覧ください。
RVCを起動しモデル推論タブを選択
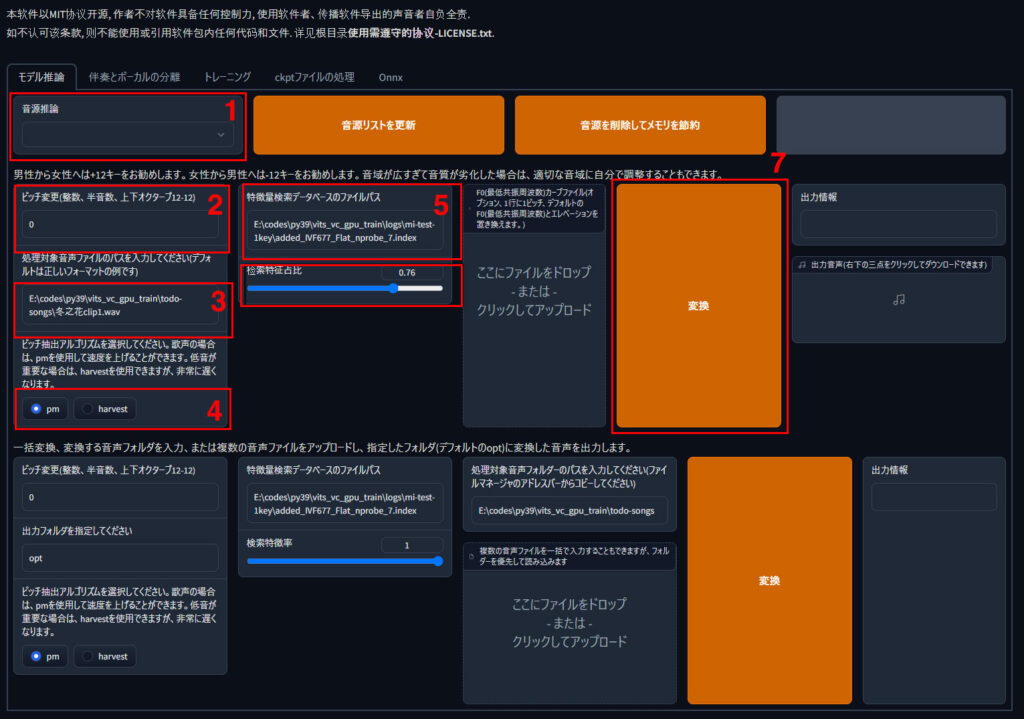
1.モデルデータの読み込み
普通に起動すると、「モデル推論」タブになっていると思います。ここで右上の音源推論に生成した音声モデルを選択します。特にフォルダ構成などは意識せず、RVCで学習を行っているのであれば、自動的に読み込まれます。もし学習してすぐに利用したい場合は、音源リストを更新を押すとモデルデータを読み込んでくれます。
2.ピッチの変更
ピッチについてはベースの音源と学習モデルの声によって調整になりますが、同性間の変換の場合は、そこまで大きく触らずで問題ないですが、男性→女性と変換する場合は+12キーと大きく設定する必要があります。
3.変換する音声を指定
変換する元のデータを指定します。パスをコピーしてコピペすればOKです。ディフォルトで例が表示されています。シンプルに音声データのパスをコピーすればOKです。
4.ピッチ抽出のアルゴリズムを選択
「pm」か「harvest」を選択します。歌唱などは「pm」で変換しないとうまくいきませんでした。音声の声質によって変更してみましょう。
5.特徴量検索データベースのファイルパス
こちらは選択してもしなくても音声変換は可能ですが、学習した際に同時に出力される.indexファイルへのパスを設定しましょう。
6.检索特征占比
大きいとモデルの声に近くなる代わり、に滑舌などが悪くなります。推論する元データに応じて変更してみるのが良いと思います。一定のリズムでの読み原稿などではそこまで高くする必要はありません。
7.変換
変換ボタンを押せば変換が開始され、出力音声欄に音声が出力されます。ダウンロードも可能なので上手く行ったファイルがあればダウンロードしておきましょう。
次回はリアルタイムに音声を変換する方法について解説したいと思います。









