進化したRVC、RVC v2での音声機械学習方法

「音声学習のRVCに、新たな学習モデルRVC v2が追加」と言う記事で、音声学習RVCの新たなモデルRVC v2のインストール方法について触れましが、今回はRVC v2を利用して、音声学習をするための手順とパラメータ設定についてまとめていきたいと思います。
RVCを起動しトレーニングタブを選択
音声学習を行うためには、RVCを起動し、「トレーニング」タブを選択。選択すると以下のようなインターフェイスが表示されます。
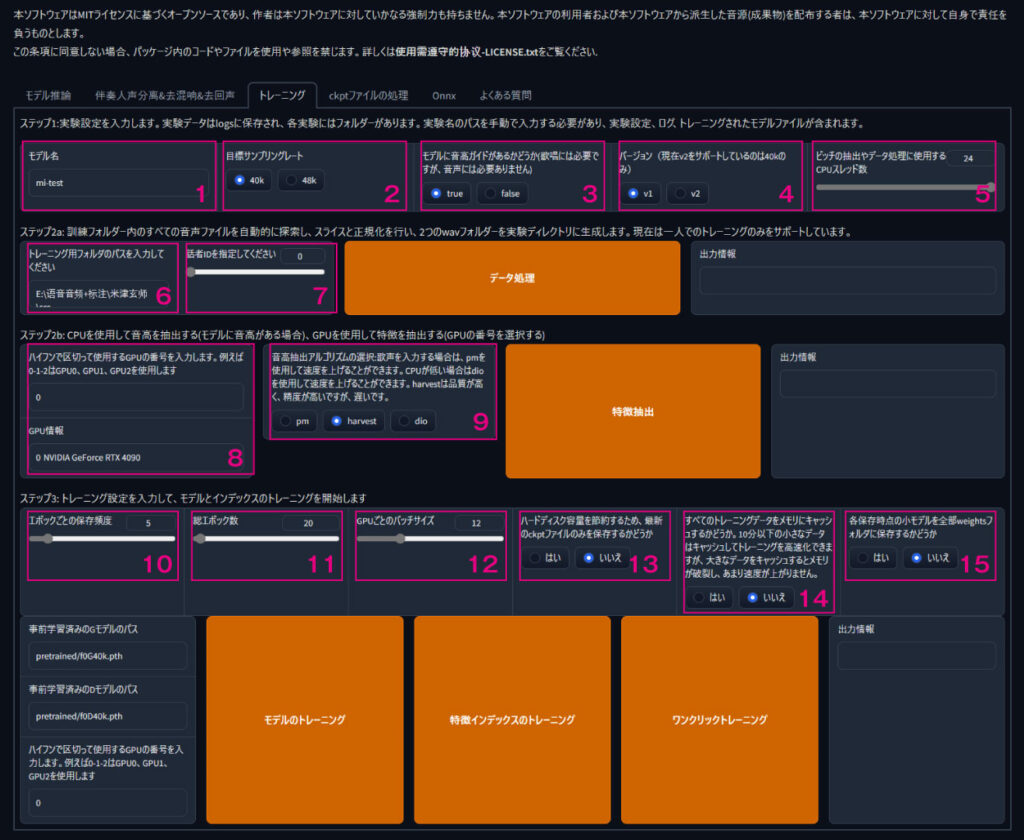
RVC v2を利用する前提で、各項目ついて一つずつ解説していきます。
1.モデル名
生成したい任意のモデル名を入力します。
2.目標サンプリングレート
RVC v2で学習させたい場合は、まだモデル自体が40Kしか対応していなため、必ず40Kを選択しましょう。
3.高音ガイドの可否
歌わせなければfalseで良いとされていますが、セリフなど抑揚があるものに関してモデル推論するならtureのほうが良い
4.バージョン
今回はv2で設定するため、v2を選択しましょう
5.CPUスレッド数
基本的にはディフォルトでOK
6.トレーニング用フォルダのパス
ディフォルトの値が入っているので、トレーニング用の音声データがあるフォルダのパスをコピーしましょう。
7.話者のID
こちらは0を選択してください。
8.GPU番号とGPU情報
基本ディフォルトで読み込まれます。2枚積んでいるというかた以外はディフォルトのママでOK
9.音高抽出アルゴリズム
こちらは基本はharvestを選択。スペックが足りない場合はpmやdioを選択しましょう。
10.エポックごとの保存頻度
どのくらいの間隔で途中で保存するかを選択できます。
11.総エポック数
何回トレーニングするか、高すぎても低すぎて品質は良くなりません。用意した素材数とも密接に関わるため色々試してみましょう。
12.GPUごとのバッチサイズ
バッチが高ければ高いほど、同時に処理してくれます。正規化の効果もあるようで、一節にはVRAMが許す限り上げたほうが良いという報告も
13.途中ファイルをどこまで残すか?
基本は最新のみでOKですが、すべての履歴を残したい場合は「いいえ」を選択
14.学習データのメモリキャッシュ
積んでいるメモリと学習データの容量との相談で決定
15.途中で保存したモデルデータの保存有無
エポックごとに推移を確かめたいときは「はい」
音声学習の開始
設定が完了したら、ワンクリックトレーニングを押せば、データ処理、特徴抽出、モデルトレーニングなど、必要な項目を一式で実行してくれます。
完了するとRVC v1と同じく「全流程结束!」という文字が出力情報に出現し、モデルデータが格納されます。