声の機械学習をRVCで実施する方法

本記事はRVC v1での機械学習の解説となります。直近リリースされたRVC v2での機械学習方法については「進化したRVC、RVC v2での音声機械学習方法」をご覧ください。
インストール、から学習データの下準備までを「声の機械学習が短時間で、効率的にできるRVC WebUIをインストール方法まとめ」や「RVC web UIの機械学習についての学習用データの準備」で紹介してきましたが、いよいよ今回は声の学習を行っていきます。
音声ファイルが準備できたらRVCのを起動し、トレーニングのタブを開きます。トレーニングの設定を一つずつ解説していきます。
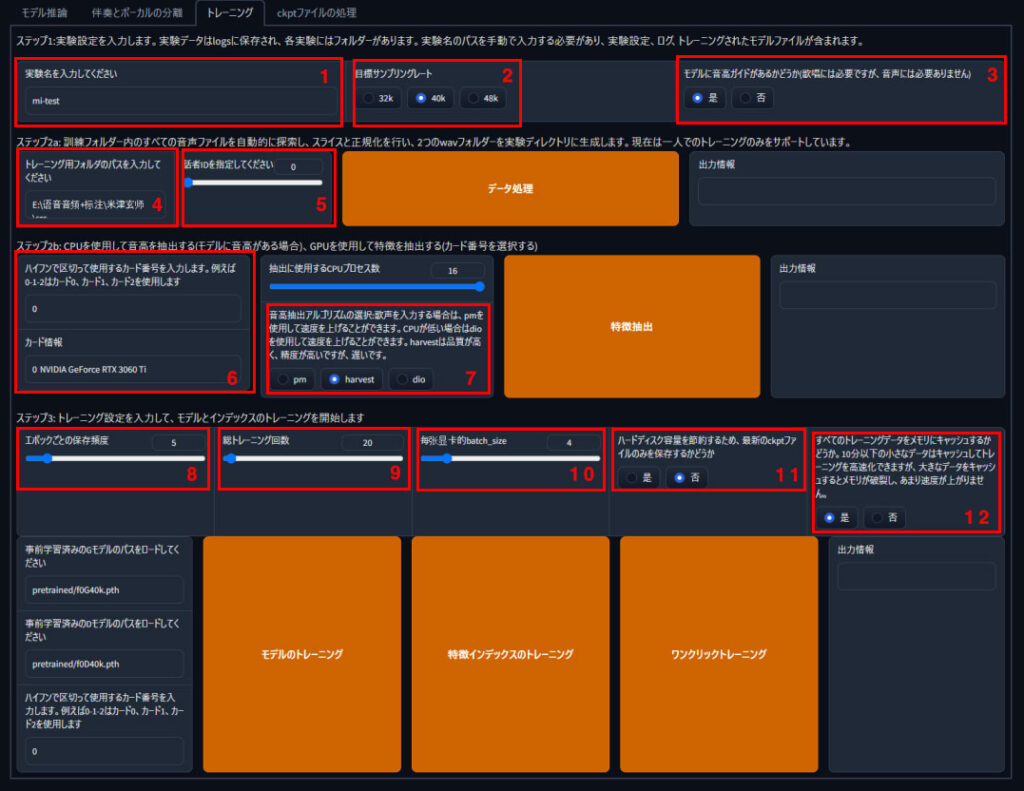
1.実験名
モデル名を入れる欄です。
最終出力するためのモデル名をいれてください。わかり易い名前であれば何でもいいですが最適な学習結果を得るために何度か条件を変えて学習することになるので、ver情報などは含めても良さそう。
2.目標サンプリングレート
32K,40k,48Kと選択することが可能です。最適な数値は学習データや用途によって異なります。
3.モデルに音高ガイド
利用用途が歌唱であれば是、喋るだけであれば否を選択します。
4.トレーニング用フォルダパス
学習用のフォルダの場所を指定します。スクリーンショットのように初期パスが入っているので上書してください。パスを入力ししてください。windowsであれば右クリックからパスのコピーからが便利。
5.話者ID
こちらはまだ1人しか対応していないため「0」のママを指定。
6.カード情報
基本的には自動で読み込まれます。複数枚のグラフィックカードを積んでいる場合は選択することが可能です。
7.抽出モデルの選択
音声抽出のアルゴリズムを選択します。GPUを搭載のPCで質を高めたい方はharvestを選択。
8.エポックごとの保存頻度
入力した数字ごとのエポックを途中データとして保存します。途中でエラーが起きたと時のために、どのくらい細かくバックアップ取るかを選択できます。
9.総トレーニング回数
あまり大きな数字をいれると膨大な時間がかかるのと、過学習となり、多ければ多いほど品質があがるというものではないので、色々と試してみてください。一般的にサンプルとなる学習データが少ない場合は多めに、サンプル数が多い場合は少なくても品質は上がる傾向にあるそうです。
10.バッチサイズ
一回の処理をいくつずつにするか?あまりにも多いとスペックが足りない場合エラーとなるため、適切な数字はPCの数字に合わせて調整してみてください。
11.バックアップファイルを常に残すかどうか?
途中のモデルデータファイルを捨てるかどうか、学習データが大きくなるとファイルサイズも大きくなるため、お使いのハードウェアに応じて設定しましょう。
12.トレーニングデータをメモリにキャッシュするか?
どのくらいのデータの学習データを使うによって異なりますが、メモリが許すのであれば「是」としたほうが良さそうです。
残りの「事前学習済みのGモデルのパスをロードしてください」「事前学習済みのDモデルのパスをロードしてください」などの項目は自動で上記の項目を触ると変更されます。
設定を終えたらワンクリックトレーニング
ワンクリックトレーニングを選択すると、ステップをすべて項目を自動で実行してくれます。エラーなどが出なければ、あとは待つだけで音声のモデルファイルが出力されます。
完了すると「全流程结束!」という文字が出力情報に出現し、モデルデータが格納されます。
次回はこのモデルデータを利用して音声ファイルを出力するまでを紹介します。










