日本語セリフも読める音声AI「Style-Bert-VITS2」で音声合成を試す

先日、「日本語セリフも読める音声合成AI「Style-Bert-VITS2」をインストール」と言う記事で、Style-Bert-VITS2のインストール方法について紹介しましたが、今回はStyle-Bert-VITS2を利用して音声合成を行う手順をまとめていきたいと思います。
Style-Bert-VITS2を起動
Style-Bert-VITS2をインストール時には自動的に立ち上がってきましたが、2回目以降の起動は「Style-Bert-VITS2」フォルダ内の「App.bat」を実行して起動します。
「App.bat」を実行した後に表示される、 local URLをクリックすれば起動が完了です。
音声のモデルを選択・ロード
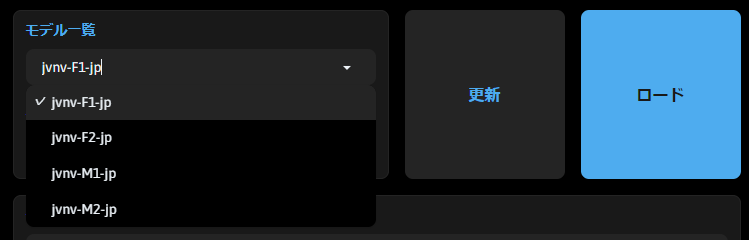
起動したら、音声モデルを選択しロードします。ディフォルトでは、4種類のモデルが用意されており、jvnv-F1-jp、jvnv-F2-jpが女性、jvnv-M1-jp、jvnv-M2-jpが男性となります。UIにも記載されていますが、初期からあるjvnvのモデルは、JVNVコーパス(言語音声と非言語音声を持つ日本語感情音声コーパス)で学習されたモデルです。ライセンスはCC BY-SA 4.0となりますのでご注意ください。
読み込みたいモデルが決まったらロードボタンを押してモデルをセットします。
読み上げたいテキストを入力
読み上げるセリフはテキストボックスに入力します。特別なことはありませんが、改行で分けて生成にチェックをいれておくとより感情を載せて読み上げてくれます。
スタイルの設定
画面右側でスタイルについて調整可能です。プリセットまたは音声ファイルから読み上げの声音・感情・スタイルのようなものを制御できます。デフォルトのNeutralでも、十分に読み上げる文に応じた感情で感情豊かに読み上げが可能です。

強さを大きくしすぎると発音が変になったり声にならなかったりと崩壊することがあり、どのくらいに強さがいいかはモデルやスタイルによって異なるようです。音声ファイルを入力する場合は、学習データと似た声音の話者(特に同じ性別)でないとよい効果が出ないとも記載されています。
プリセットは以下の7つがセットされています。
・Neutral
・Angry
・Disgust
・Fear
・Happy
・Sad
・Surprise
音声合成
ここまでセットができたら、あとは音声合成ボタンを押すだけです。4090の環境では1行程度だと数秒で合成が完了します。音声ファイルは書き出すことも可能でダウンロードボタンを押せばwav形式で保存可能です。

Style-Bert-VITS2
https://github.com/litagin02/Style-Bert-VITS2